
Poichè la lista, come ogni struttura dati, serve per memorizzare informazioni utili, ogni nodo della lista deve innanzitutto contenere uno spazio destinato ad alloggiare un dato. Questo spazio è spesso detto “campo informativo” del nodo.
Se il nodo non contenesse altro che questo la sua utilità non
sarebbe maggiore di quella di una normale variabile dello stesso tipo
usato
per il campo informativo. In particolare, i vari nodi sarebbero
entità
di per sè scorrelate tra loro, proprio come tante variabili,
appunto.
Ciò che manca per dare valore aggiunto al nodo sono informazioni
addizionali che consentano il collegamento verso altri nodi.
In una lista semplice, o “singola”, ogni nodo contiene infatti anche il puntatore al nodo successivo (next).

Ecco una possibile dichiarazione C di un nodo come quello sopra raffigurato:

Qui si suppone che il campo informativo del nodo sia un numero intero. Per ospitarlo è quindi stato dichiarato un campo chiamato campo_informativo (il nome, naturalmente, avrebbe potuto essere qualsiasi altro identificatore valido) di tipo int. Per il puntatore al prossimo nodo si deve invece dichiarare un puntatore a una struttura dello stesso tipo di questo nodo (supponiamo naturalmente che tutti i nodi di una stessa lista siano fatti allo stesso modo, siano cioè dello stesso tipo!). Per consuetudine e per brevità a questo puntatore si dà il nome di next, ma, ancora, qualunque nome sintatticamente valido (per esempio: prossimo) sarebbe andato altrettanto bene.
In una lista doppia ogni nodo contiene invece due puntatori: uno al nodo successivo (di solito chiamato next), come nelle liste singole, e uno al nodo precedente (di solito chiamato previous o prev, qualche volta last).

Ecco una ipotesi di dichiarazione per il tipo di dato corrispondente

Per mantenere la possibilità di accedere alla lista, al
programma
principale è sufficiente mantenere un puntatore al primo
elemento
(“testa” o “head”) della lista e (solo per liste doppie) un secondo
puntatore
all’ultimo elemento (“coda” o “tail”) della lista. Questi puntatori
possono
essere mantenuti in variabili globali del programma per permetterne
l’uso
da parte di tutte le funzioni del programma stesso, oppure possono
essere
passati alle funzioni che di volta in volta dovranno operare sulla
lista.
Poichè ogni nodo di una lista singola ha un puntatore al nodo
successivo, nell’ultimo nodo, che non è seguito da alcun
altro nodo, al puntatore “next” si attribuisce di solito
convenzionalmente
il valore NULL, un indirizzo di memoria normalmente non
valido
usato in questo caso per indicare che la lista è terminata. Se
un
puntatore contiene NULL vuol dire, convenzionalmente, che non
punta da nessuna parte utile (in realtà punta all'indirizzo il
cui
valore è pari al valore della costante NULL, ma
siccome
NULL
è scelto in modo tale che l'indirizzo da esso rappresentato sia
un indirizzo su cui è normalmente vietato l'accesso, non si
corre
il rischio di scambiare l'indirizzo di una locazione di memoria valida
con la costante NULL). NULL è una costante
definita
in stdio.h. Questa costante vale 0 su tutti i sistemi
più noti, ma nel programma non è corretto fare
affidamento su
questo fatto e si deve quindi sempre fare confronti con NULL
e
non con 0 se si vuole che il programma possa essere compilato senza
modificarlo
e fatto girare su un sistema sul quale NULL non vale 0.
Le liste
doppie hanno in più una situazione simile all’inizio della
lista,
dove non esiste un nodo precedente; in questo caso il puntatore “last”
del primo nodo contiene NULL. Il fatto che un puntatore
contenga
NULL
(e non porti quindi da nessuna parte..) viene spesso rappresentato, un
po’ impropriamente ma in modo graficamente efficace, con il simbolo
elettrotecnico
di “messa a terra” o “collegamento a massa”.
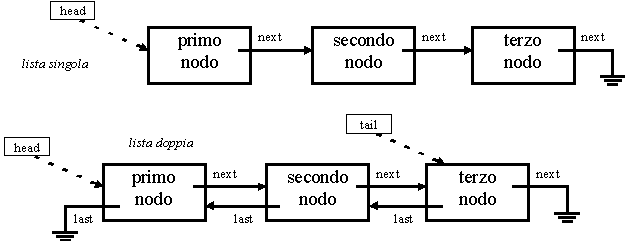
Grazie ai puntatori “next” tra i nodi è possibile scorrere il
contenuto di una lista secondo l’ordinamento che tali puntatori
implicitamente
definiscono; nel caso di lista doppia è inoltre possibile
percorrere
la lista anche nella direzione opposta all’ordinamento, seguendo i
puntatori
“last”. Spesso l’ordinamento realizzato grazie ai puntatori è
sfruttato
per mantenere un parallelo ordinamento dei nodi, riferito al valore
contenuto
nel campo informativo di ciascun nodo. In questo caso si parla di
“lista
ordinata”.
La lista è in realtà sempre di per sè ordinata
perchè i puntatori tra i nodi definiscono implicitamente un
ordinamento
topologico tra di essi. Quando però l’ordinamento realizzato dai
puntatori tra i nodi viene fatto corrispondere a un ordinamento sul
valore
contenuto nei nodi, la proprietà di ordinamento tipica di ogni
lista
viene effettivamente sfruttata e si rimarca questo fatto parlando di
lista
ordinata.
In certe applicazioni non interessa sfruttare la proprietà delle
liste di mantenere e rappresentare un ordinamento tra i loro membri,
perchè
è sufficiente sfruttarne la capacità di contenere un
numero
variabile, a priori ignoto, di oggetti (proprietà che manca agli
array). Per esempio: mantenere un elenco delle persone iscritte a un
certo
servizio, senza bisogno di mantenerle in ordine alfabetico.
Va anche detto che se la routine che inserisce i nodi nella lista
è
sempre la stessa e funziona sempre allo stesso modo (per esempio se
inserisce
i nodi sempre alla fine della lista), allora la lista mantiene
implicitamente
un ordinamento cronologico sui suoi elementi: gli elementi aggiunti
prima
precederanno gli elementi aggiunti dopo; l'elemento più vecchio
mai aggiunto alla lista sarà il primo nodo della lista, il
più
recente sarà l'ultimo.
La lista consente quindi di mantenere in memoria una sequenza ordinata di elementi e di scorrerla leggendone il contenuto sempre sequenzialmente (seguendo in modo opportuno i puntatori che collegano tra loro i nodi della lista). Queste proprietà caratterizzano, per la verità, anche un array il cui contenuto sia stato ordinato. Le liste hanno però, rispetto agli array, la proprietà di rendere semplice e veloce l’inserimento e la rimozione di nuovi elementi al loro giusto posto nella sequenza ordinata. Infatti, mentre in un array ordinato l’inserimento di un nodo alla giusta posizione richiede di spostare in giù tutti gli altri elementi per fare spazio (un’operazione che richiede essenzialmente un ciclo for di “copiatura” tanto più lungo quanto più numerosi sono gli elementi da spostare presenti nell’array), in una lista singola, per inserire un nuovo nodo alla giusta posizione, è sempre sufficiente risistemare i valori di al più 2 puntatori (4 nella lista doppia), e questo indipendentemente dal numero di elementi contenuti nella lista e dalla posizione alla quale si intende inserire il nuovo nodo.
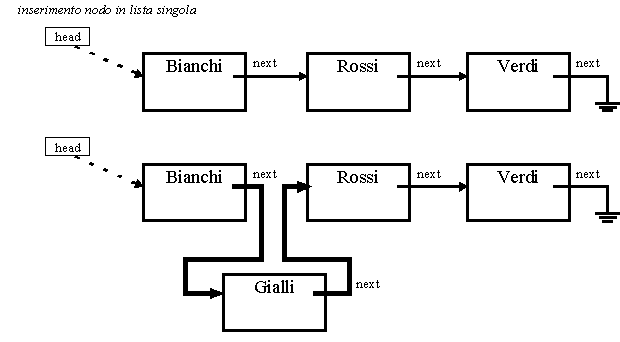
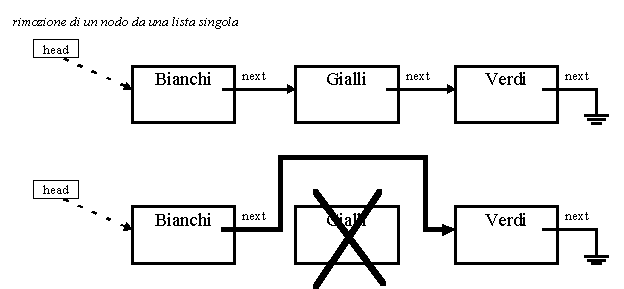
Nei seguenti due esempi vediamo l'inserimento e la rimozione di un nodo in una lista singola.
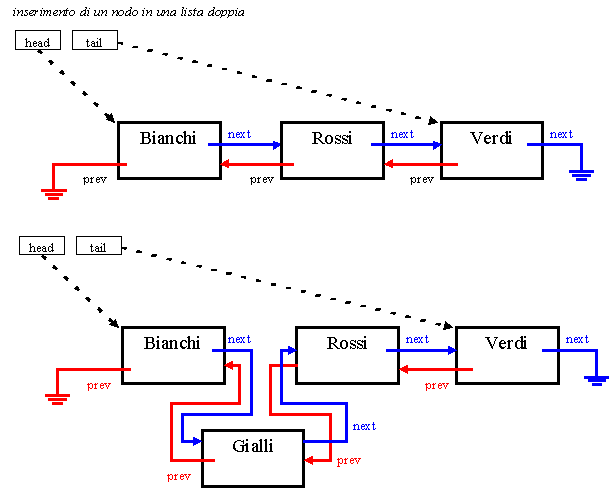
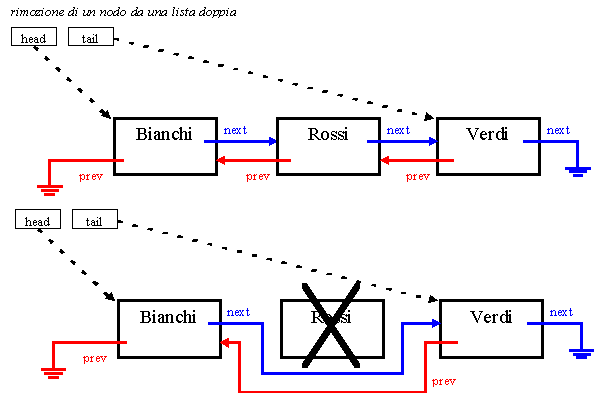
I seguenti due schemi mostrano l'effetto delle operazioni di inserimento e di rimozione in liste doppie. Per maggior chiarezza la catena dei puntatori "next" è colorata in blu e quella dei puntatori "prev" è colorata in rosso.
Un altro vantaggio delle liste rispetto agli array sta nel fatto che le liste consumano una quantità di memoria proporzionale al numero di elementi effettivamente presenti nella struttura dati. Gli array invece devono essere dimensionati dall’inizio in modo che siano abbastanza grandi per contenere il massimo numero di elementi che ci si aspetta che il programma avrà bisogno di memorizzare. A differenza di una lista, un array occupa quindi sempre il massimo spazio previsto, anche se contiene pochi elementi.